

AI technologies are increasingly being integrated in scientific databases. We have summarized the advantages and disadvantages of AI technologies in databases and explain, how this option can be used effectively.
In addition to content summaries and the in-depth exploration of documents, the use of AI in scientific databases also involves a Natural Language Search (NLS). This search mode is an (optional) component of the Simple or Advanced Search and allows search queries to be formulated in everyday language.
The NLS mode uses Natural Language Understanding (NLU) to understand the intent and contextual clues in a query. This function is particularly beneficial for less experienced database users.
As an example, we have tested the use of Natural Language Search in the Ebsco database Academic Search Premier. In addition to the usual search modes, you can also select NLS in the simple search.
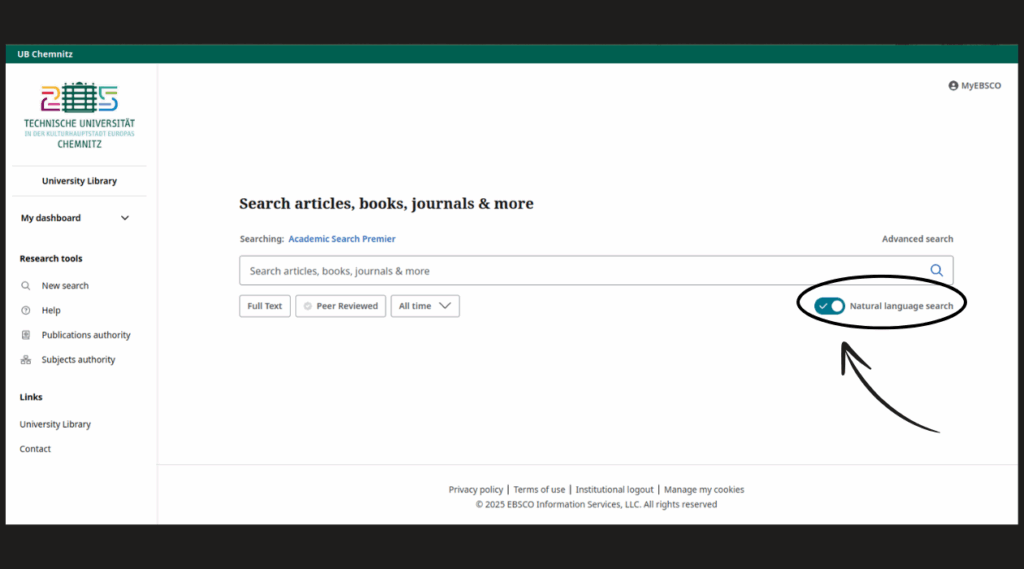
The query entered is displayed above the result list as a search string with linked search terms (show refined query). However, the search is only carried out within simple search mode, which means that important search results could be overlooked. An advanced search provides a more detailed overview.
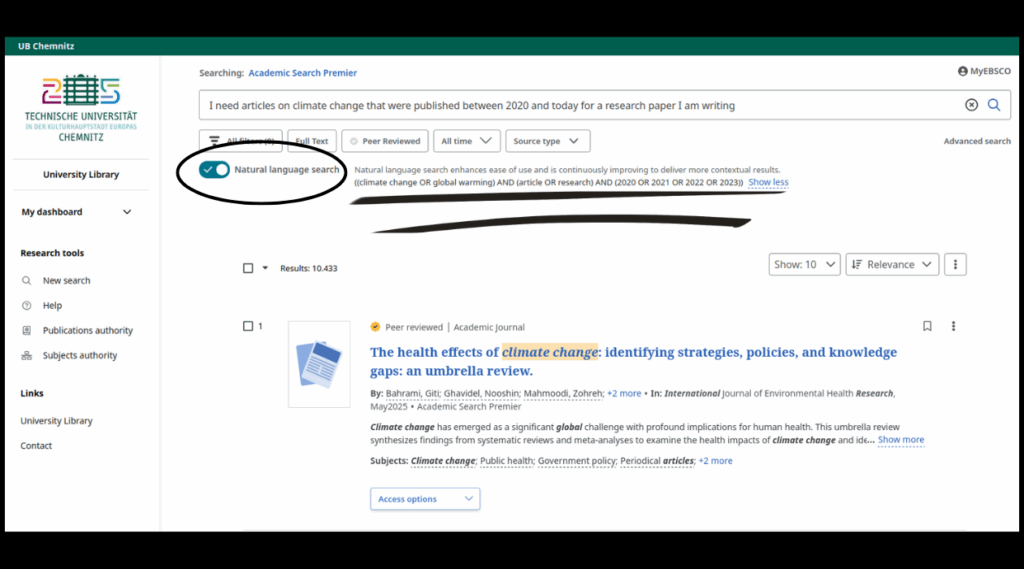
Due to the simple search mode, formal search criteria or filters are not recognized at the moment. Here are two examples of NLS search queries and their counterparts.
Example 1: “Show all articles from 2020 that contain the keyword automation in the abstract”. This is transformed into a search string as follows: automation AND (abstract) AND (2020).
Example 2: “I need articles on climate change that were published between 2020 and today for a research paper I am writing” is transformed into the search string: ((climate change OR global warming) AND (article OR research) AND (2020 OR 2021 OR 2022 OR 2023)).
Filters such as “Source Type” or “Publication Date” are not recognized. Furthermore, in example 2, the time period is not set to include 2024 or 2025, although the keyword “today” was used. It could be due to the status of the training data for the AI. This can also lead to important search results being overlooked.
The NLS search finds a maximum of two alternative search terms for one search aspect. Deeper filtering, e.g. to limit results to articles from a specific journal (publication), is not possible in the NLS.
Of course, AI technologies in databases are constantly evolving, so this information can quickly become outdated.
Another database that uses AI technology to support the research process is Statista. Here, the “Research AI” tab offers the option to search in natural language (except for the content of Consumer Insights and Company Insights). There are examples of prompts that can help you to interact effectively with the AI. In Statista, the results found are summarized by the Large Language Model (LLM) Claude 3 Sonnet and the sources used are indicated below the summary.
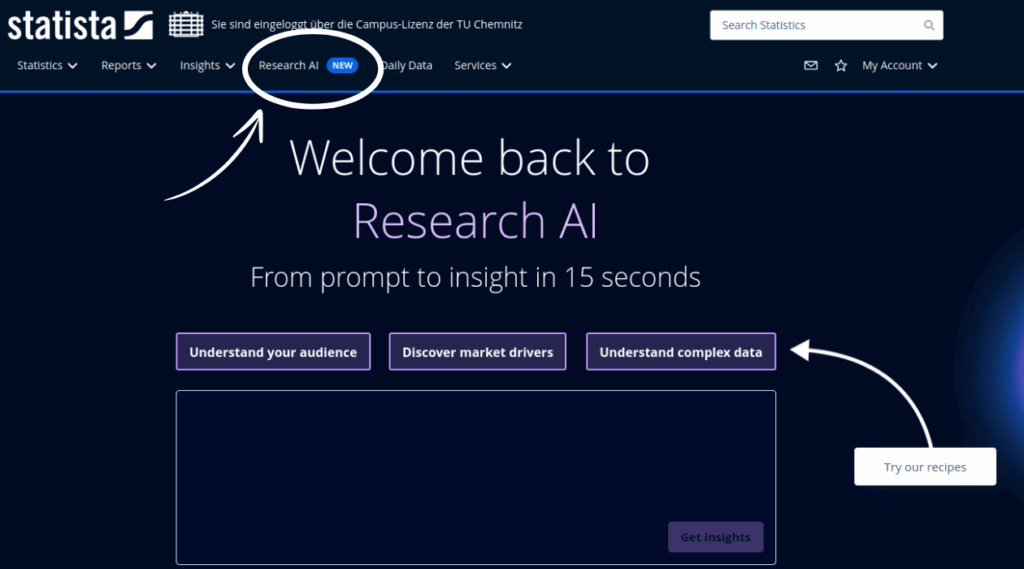
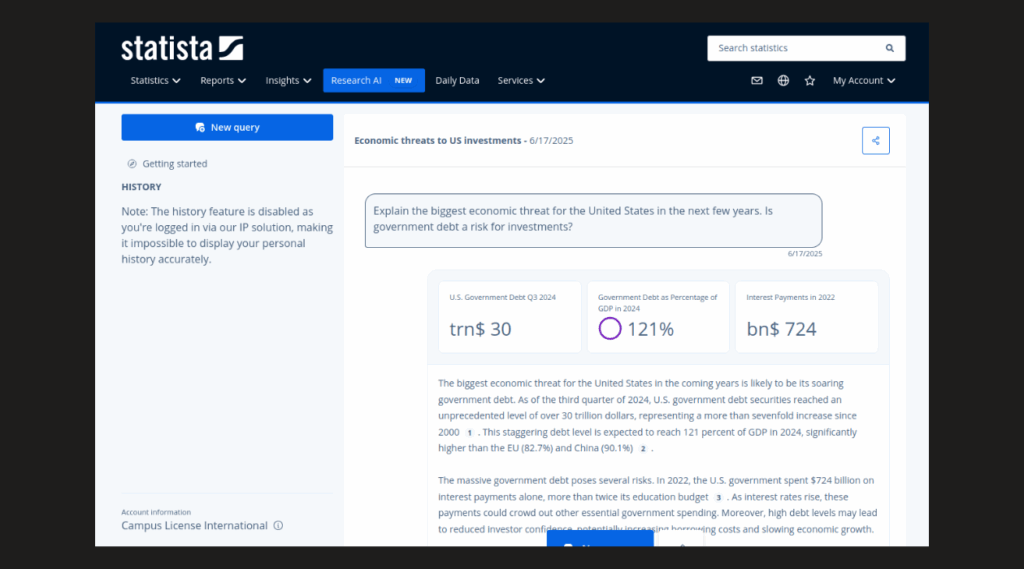
Unfortunately, this database does not provide the search terms to track how and where searches were carried out. Possible follow-up questions are suggested to users for further exploration of the topic.
Other databases that already use AI to support searches are Web of Science (Smart Search: free of charge & already available; Web of Science Research Assistant: fee-based, not yet included in the license), ScienceDirect (ScienceDirect AI: fee-based, not yet included in the license) and Scopus (Scopus AI, fee-based, not yet included in the license).
The rules of prompting (entering a query) can also be helpful for database searches. In particular, the query should be formulated clearly and precisely and avoid unnecessary filler words.
As this topic is highly discussed and very much evolving, information can quickly become outdated. Please also check the websites of the providers mentioned and contact our information desk if you have any questions.
Further information can be found here:

 Foto: Annett Kittner
Foto: Annett Kittner