

KI-Technologien werden zunehmend auch in wissenschaftlichen Datenbanken eingesetzt. Wir haben für Sie zusammengefasst, welche Vor- und Nachteile dieser Einsatz haben kann und wie man diese Option effektiv einsetzen kann.
Neben Inhaltszusammenfassungen und der tiefergehenden Exploration von Dokumenten geht es beim Einsatz von KI in wissenschaftlichen Datenbanken auch um eine Natural Language Search (NLS). Dieser Suchmodus ist ein (optionaler) Bestandteil der Einfachen oder Erweiterten Suche und erlaubt es Suchanfragen in Alltagssprache zu formulieren.
Der NLS-Modus nutzt die Verarbeitung natürlicher Sprache (Natural Language Understanding, NLU), um die Absicht und kontextbezogenen Hinweise in einer Abfrage zu verstehen. Diese Funktion ist besonders vorteilhaft für noch wenig erfahrene Datenbanknutzerinnen und -nutzer.
Beispielhaft haben wir den Einsatz der Suche in natürlicher Sprache in den Ebsco-Datenbanken getestet. Dort kann man in der Einfachen Suche, neben den üblichen Suchmodi, auch die NLS auswählen.
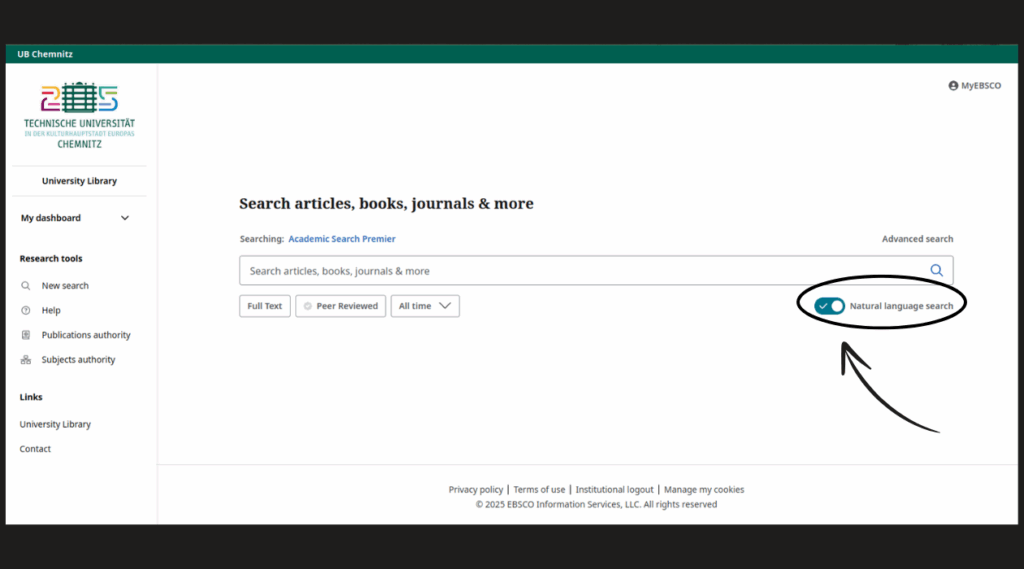
Die eingegebene Anfrage wird über der Trefferliste zusätzlich auch als Suchstring mit verknüpften Suchbegriffen angezeigt (show refined query). Jedoch erfolgt die Suche nur im einfachen Suchmodus, wodurch wichtige Rechercheergebnisse übersehen werden könnten. Eine Erweiterte Suche ermöglicht einen detaillierteren Überblick.
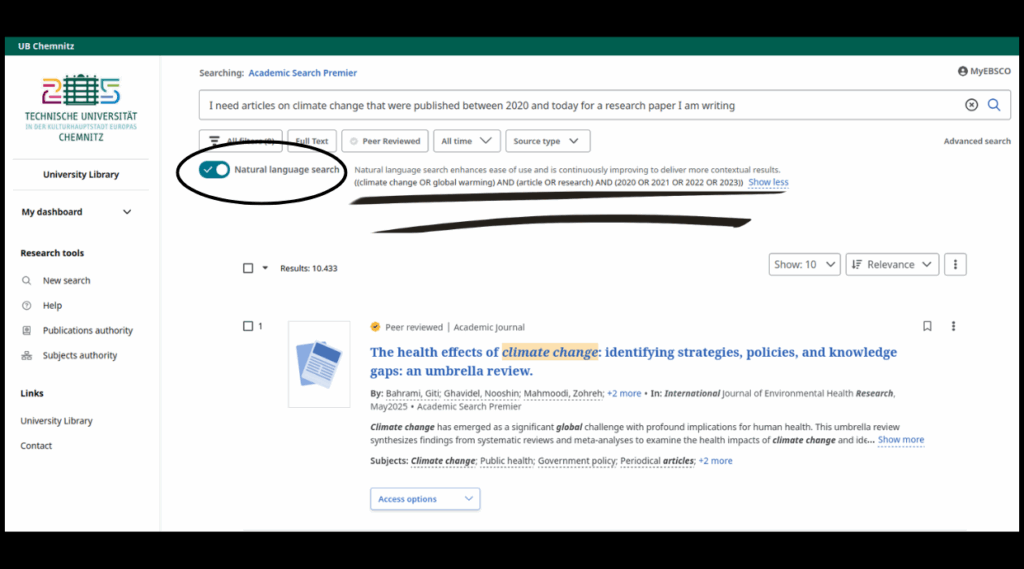
Aufgrund des einfachen Suchmodus werden im Moment auch formale Suchkriterien bzw. Filter nicht erkannt. Hier zwei Beispiele für NLS Suchanfragen und deren Pendant.
Beispiel 1: „Show all articles from 2020 that contain the keyword automation in the abstract“. Dies wird wie folgt in einen Suchstring übersetzt: automation AND (abstract) AND (2020).
Beispiel 2: Bei der Anfrage „I need articles on climate change that were published between 2020 and today for a research paper I am writing“ wird nach folgenden Schlagworten gesucht: ((climate change OR global warming) AND (article OR research) AND (2020 OR 2021 OR 2022 OR 2023)).
Filter wie „Source Type“ oder „Publication Date“ werden nicht erkannt. Ferner wird bei Beispiel 2 der Zeitraum nicht bis 2025 gesetzt, obwohl das Stichwort „today“ verwendet wurde. Dies könnte mit dem Stand der Trainigsdaten für die KI zusammenhängen. Hierdurch können ebenfalls wichtige Rechercheergebnisse übersehen werden.
Über die NLS-Suche werden höchstens zwei alternative Suchbegriffe für einen Suchaspekt gefunden. Eine tiefergehende Filterung, z.B. zur Trefferbegrenzung auf Artikel aus einer bestimmten Zeitschrift (publication) ist in der NLS nicht möglich.
Natürlich werden KI-Technologien in Datenbanken fortwährend weiterentwickelt, so dass diese Informationen schnell veraltet sein können.
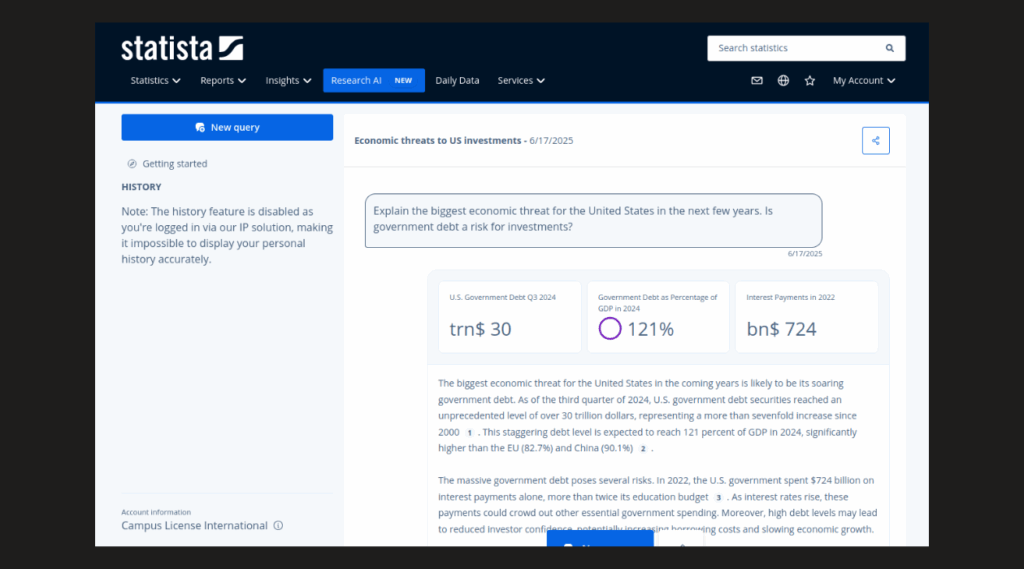
Eine weitere Datenbank, die KI-Technologie zur Unterstützung im Rechercheprozess einsetzt, ist Statista. Hier bietet der Reiter „Research AI“ die Möglichkeit in natürlicher Sprache zu suchen (ausgenommen sind die Inhalte von Consumer Insights und Company Insights). Es gibt Beispiele für Prompts, die dabei helfen können, effektiv mit der KI zu interagieren. In Statista werden die gefundenen Ergebnisse vom Large Language Model (LLM) Claude 3 Sonnet zusammengefasst und die genutzten Quellen werden unterhalb der Zusammenfassung angegeben.
In dieser Datenbank gibt es leider keine Möglichkeit, anhand von Suchbegriffen nachzuvollziehen, wie und wo gesucht wurde. Zur weiteren Exploration des Themas werden den Nutzerinnen und Nutzern mögliche Anschlussfragen vorgeschlagen.
Weitere Datenbanken die bereits jetzt oder zukünftig KI-Technologien zur Rechercheunterstützung einsetzen sind Web of Science (Smart Search: kostenfrei & bereits einsetzbar; Web of Science Research Assistant: kostenpflichtig, noch nicht in der Lizenz enthalten), ScienceDirect (ScienceDirect AI: kostenpflichtig, noch nicht in der Lizenz enthalten) und Scopus (Scopus AI, kostenpflichtig, noch nicht in der Lizenz enthalten).
Auch bei einer Datenbankrecherche können die Regeln des Promptings (die Eingabe einer Anfrage) hilfreich sein. Insbesondere sollte die Anfrage einfach, klar und präzise formuliert sein und unnötige Füllwörter vermeiden.
Da dieses Thema hochaktuell und sehr im Fluss ist, können Informationen schnell veraltet sein. Bitte informieren Sie sich zusätzlich auf den Seiten der genannten Anbieter und kontaktieren Sie bei Fragen unsere Auskunft.
Weiterführende Informationen finden Sie hier:
 Foto: Annett Kittner
Foto: Annett Kittner

